redis bgrewriteaof问题
一、背景
AOF:
Redis的AOF机制有点类似于Mysql binlog,是Redis的提供的一种持久化方式(另一种是RDB),
它会将所有的写命令按照一定频率(no, always, every seconds)写入到日志文件中,当Redis停机
重启后恢复数据库。
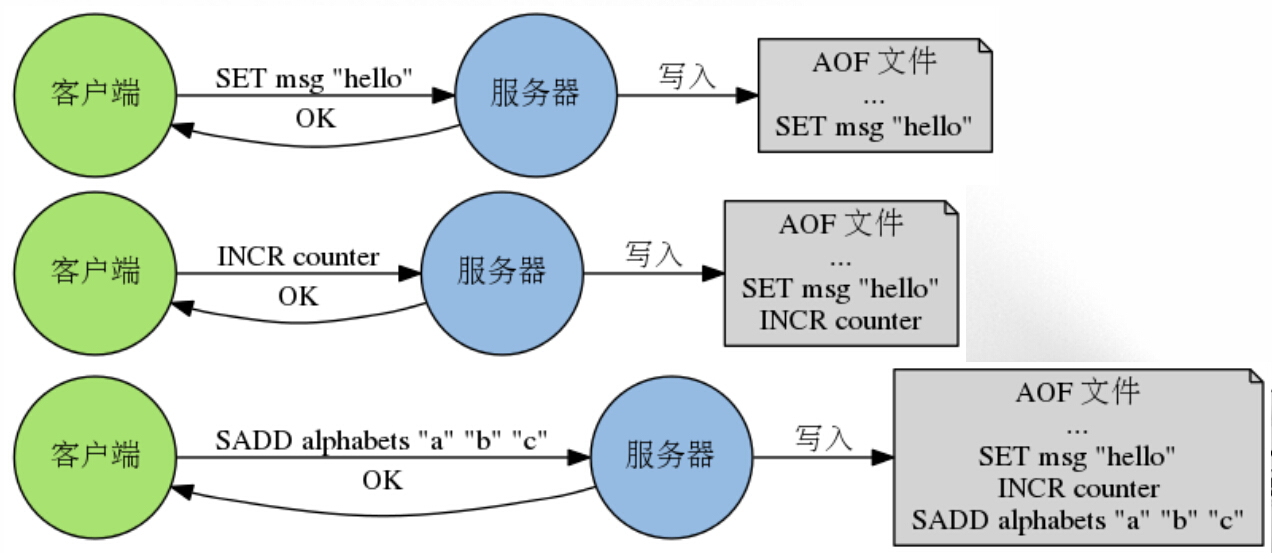
AOF重写:
(1) 随着AOF文件越来越大,里面会有大部分是重复命令或者可以合并的命令(100次incr = set key 100)
(2) 重写的好处:减少AOF日志尺寸,减少内存占用,加快数据库恢复时间。

二、单机多实例可能存在Swap和OOM的隐患:
由于Redis的单线程模型,理论上每个redis实例只会用到一个CPU, 也就是说可以在一台多核的服务器上
部署多个实例(实际就是这么做的)。但是Redis的AOF重写是通过fork出一个Redis进程来实现的,
所以有经验的Redis开发和运维人员会告诉你,在一台服务器上要预留一半的内存(防止出现AOF重写集
中发生,出现swap和OOM)。
三、最佳实践
1. meta信息:作为一个redis云系统,需要记录各个维度的数据,比如:业务组、机器、实例、应用、负责人多个维度的数据.
2. AOF的管理方式:
(1) 自动:让每个redis决定是否做AOF重写操作(根据auto-aof-rewrite-percentage和auto-aof-rewrite-min-size两个参数)
(2) crontab: 定时任务,可能仍然会出现多个redis实例,属于一种折中方案。
(3) remote集中式:
最终目标是一台机器一个时刻,只有一个redis实例进行AOF重写。
具体做法其实很简单,以机器为单位,轮询每个机器的实例,如果满足条件就运行(比如currentSize和baseSize满足什么关系)bgrewriteaof命令。
使用client list命令(类似于mysql processlist) redis-cli -h host -p port client list | grep -v “omem=0”,来查询输出缓冲区不为0的客户端连接
1 | redis-cli -h 127.0.0.1 -p 6379 client list |
四、紧急处理和解决方法
进行主从切换(主从内存使用量不一致),也就是redis-cluster的fail-over操作,继续观察新的
Master是否有异常,通过观察未出现异常。
查找到真正的原因后,也就是monitor,关闭掉monitor命令的进程后,内存很快就降下来了。